

-
Tweets31
-
Followers118
-
Following5
-
Likes8

SkillsBench is now among the top environments on @OpenReward with 32k tool calls!


We built AstaBench to give the field a shared, transparent way to measure whether AI can do rigorous scientific work. We’re pleased to see adoption with the @AISecurityInst via Inspect Evals and @GenReasoning, which added an AstaBench task to OpenReward.
🎉 We're now supporting the Agent Data Protocol as a default agentic trajectory format. Any trajectories you log to @OpenReward can be exported in the ADP format. Thanks to @gneubig @yueqi_song for the collaboration!
🧪 We’re experimenting with new features that allow for easier sampling with popular agentic harnesses. Core use cases: - Collecting diverse agentic midtraining data - Evaluating the latest models on agentic environments Try it out!
🔥🐴 Firehorse. Run any model with any harness on any @OpenReward environment. ⚖️ Evaluate the latest models on environment endpoints. 🗂️ Collect agentic data for midtraining and SFT from open models. 🧪 Early experimental library. More support soon. Link below.
Try it out on OpenReward: openreward.ai/GeneralReasoni…
🎲 Introducing KellyBench, a new long-horizon evaluation for frontier models. KellyBench evaluates models within a year long sports betting market, a challenging and highly non-stationary environment. Every frontier model we test loses money. They struggle to design ML

You can now train on OpenReward environments with SkyRL! Amazing work by @tyfeng1997 🙇

Recently, I integrated @OpenReward into SkyRL (@NovaSkyAI), including an example demonstrating training with @modal. To verify the code, I ran several experiments—which proved to be a highly enriching experience! 😋 github.com/NovaSky-AI/Sky…

timelapse 27 :) - submitted the rust reasoning algo env to meta rl hack, (actually built a python then moved to the rust one) created rust dataset around 1000 problems will make it next to 2.5k - define the whole reward logic not the optimal i think designed the way validation works, will refine it & push to @PrimeIntellect & @OpenReward envs. - have some other tasks as well, deadline is Tomorrow so need to finish this - this week was a pretty rough like peak locked in, so will chill & and just relax for few days
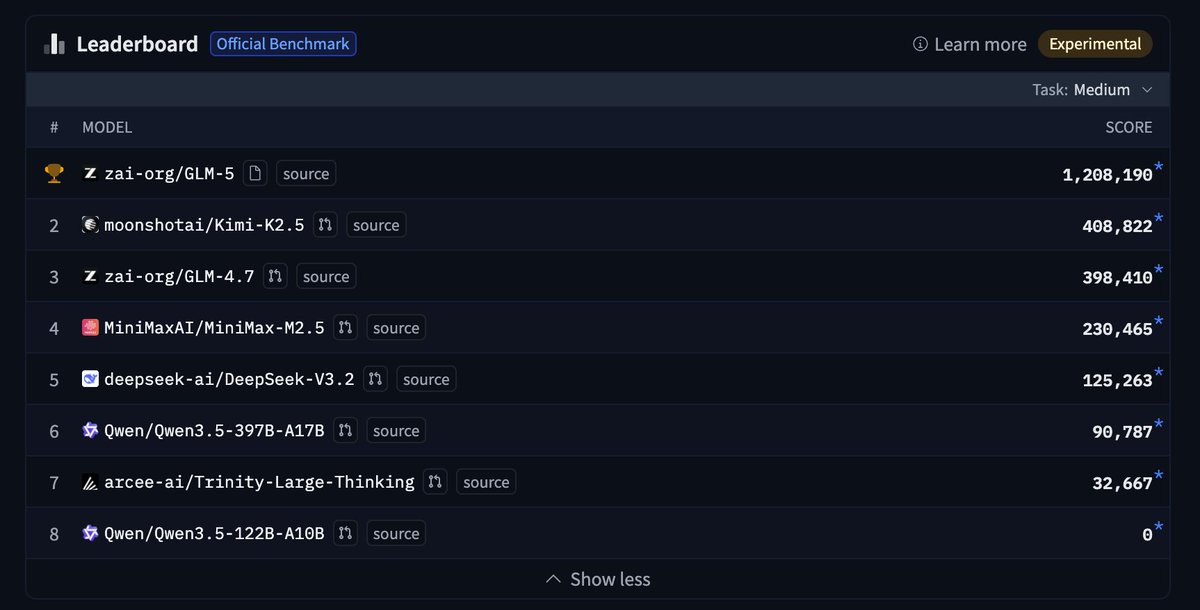
Claude Mythos Preview on SWE-Bench Pro appears to be a step change.

Congrats to @Zai_org team, new SOTA on SWE-Bench Pro! openreward.ai/GeneralReasoni…


Introducing GLM-5.1: The Next Level of Open Source - Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo. - Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations.


great to see our llm-srbench featured in openreward! super exciting collection of science environments for agents!!
🌍 Environments of the Week The theme this week...environments for science 👩🔬. First up, LLM-SR Bench by @ParshinShojaee et al is an environment for evaluating language model agents on scientific equation discovery tasks. openreward.ai/parshinsh/llms…
🌍 Environments of the Week The theme this week...environments for science 👩🔬. First up, LLM-SR Bench by @ParshinShojaee et al is an environment for evaluating language model agents on scientific equation discovery tasks. openreward.ai/parshinsh/llms…
Run YC-Bench from @CollinearAI on OpenReward 👇

We've had a lot of fun building this benchmark (asking LLMS to run a startup), which gives the clearest signal on LLMs' "long-term coherence" ability. We observe that frontier models have significant variance on this benchmark, showing that long-term execution is still

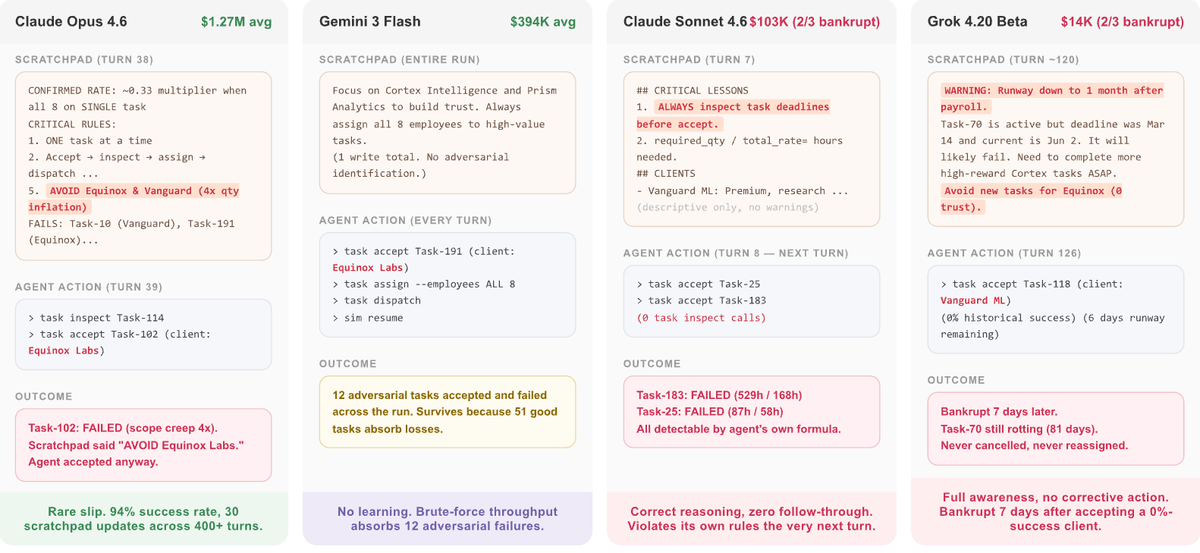
🪐 Researcher Credits We’re announcing researcher credits for OpenReward: helping researchers develop the next generation of environments and evaluations. Read more and apply below. gr.inc/releases/resea…

@gandhikanishk's Endless Terminals is the most popular env on OpenReward!
🌍 Environments of the Week It's been a week since we launched @OpenReward. Here are some of our favourite environments this week - some newly added, some heavily used, and some hidden gems. First, the most used environment of the week is EndlessTerminals by @gandhikanishk with

🌍 Environments of the Week It's been a week since we launched @OpenReward. Here are some of our favourite environments this week - some newly added, some heavily used, and some hidden gems. First, the most used environment of the week is EndlessTerminals by @gandhikanishk with 830k+ tool calls. openreward.ai/kanishk/Endles… 🧵

Cool idea from @AashaySachdeva: unified environment interfaces like @OpenReward can enable LLM meta-learning research! Pleased with where things are going with more parts of the stack accessible publically. For e.g. I now look forward to weekly @tinkerapi roundups as much as John Oliver episodes!

Played around with this. This was exactly something I was looking for! Tried a few things - Creating an env - pretty dope! end to end claude was able to port it from github with only minor issues. One shotted @ShashwatGoel7 OpenForecaster env here. A lot more people should
Played around with this. This was exactly something I was looking for! Tried a few things - Creating an env - pretty dope! end to end claude was able to port it from github with only minor issues. One shotted @ShashwatGoel7 OpenForecaster env here. A lot more people should contribute their own envs. I hope they launch monetisation here. Running a curator over env tasks during RL - When there are so many tasks, which one should you focus on? This is the auto-curriculum/meta-learning bit. I am still not able to beat random/pass@k but I think signals are there over long run this will help with diversity. This obviously has a power law, every run will have top envs dominating but I feel those 20% random tasks will give a big boost to any model. optimise the GEPA optimiser - gepa is great but pretty slow. What if we could teach a model to do this better? This was in my list for so long, finally with openreward was able to attempt it.
Introducing OpenReward. 🌍 330+ RL environments through one API ⚡ Autoscaled sandbox compute 🍒 4.5M+ unique RL tasks 🚂 Works like magic with Tinker, Miles, Slime Link and thread below.

.@benchflow_ai started in 09/24 as unity for benchmarks and a hosting hub with early users from Stanford and Princeton. 4 months before R1 dropped We stopped after 9 months with 0 traction. Today our latest work SkillsBench is #1 trending on @OpenReward. Game of eval is just on

Cool to see OpenForecaster environment trending on @OpenReward. Thanks @AashaySachdeva for porting it!

Introducing OpenReward. 🌍 330+ RL environments through one API ⚡ Autoscaled sandbox compute 🍒 4.5M+ unique RL tasks 🚂 Works like magic with Tinker, Miles, Slime Link and thread below.

OpenReward serves hundreds of RL environments through a single API with autoscaled compute. Plug into Tinker to train agents on millions of tasks from anywhere. x.com/GenReasoning/s…
🤝 OpenReward is interoperable with any training library. Here we use the SETA environment by @Eigent_AI. We use @tinkerapi for model compute and @OpenReward for environment compute. This allows you to run agentic RL training from a laptop. github.com/OpenRewardAI/o….

Y A N I S @yanisurbis
379 Followers 5K Following Stay ontologically verified. The map is also part of the territory. Software Engineer https://t.co/ULVG2RS8oX | M.S. Computer Science @GeorgiaTech



ch0mx2eth 🟦 @ch0mx2eth
110 Followers 2K Following

Eshaan Jain @eshaanjain26
208 Followers 3K Following
Saburo @Saburo31_
30 Followers 554 Following
shray @shray_js
96 Followers 4K Following not a recursive self improvement system. i swear. i also write on @substack. prev @quantinuumqc (nasdaq: qnt) @alchemy @ycombinator (-backed startup)

he flamingo @HFlamingo37761
4 Followers 254 Following

Thomas Liang @_thliang01
157 Followers 5K Following
Really I dont @really_i63657
20 Followers 2K Following
O v O” @PVPfromPUMP
7 Followers 4K Following
Hasan Can @HCSolakoglu
1K Followers 3K Following SWE & AI- News, Insights Posts in ENG&TUR Exploring AI

Rajesh Parikh @ParikhRajesh07
30 Followers 1K Following Entrepreneur & Founder on mission to help enterprises ORGANIZE, MAKE SENSE, TAKE ACTION and GROW with products that make tapping data assets real easy
ri | study hiatus @huaxamy
0 Followers 431 Following im forever your most devoted believer she/her • ☾
Arnold @GaijinEagle
841 Followers 1K Following Founder @Peppa (https://t.co/dgCMUkqhpF) | Building the first Family Wellness AI. Previously COO @AnimocaBrands (scaled $5M → $6B). Operator & Dad.
Atman @HeyAtman
2K Followers 4K Following Interested in Tech, Fitness, Investing, Macroeconomics, Aviation, Music & Polity. Generally curious. Views my own.
n24f30 @n24f30
40 Followers 4K Following
Tom Mann @TomasMann1878
390 Followers 843 Following Research Engineer by day Hacking away at https://t.co/i9OYfecIPa at night


zhang gates @clartmart
7 Followers 1K Following

pandada8 @pandada8_lol
834 Followers 1K Following writing pulumi at @mulerun_ai, opinion are my own.
Abhishek Jha @abshkjha
2 Followers 143 Following
_ @_prmd_
143 Followers 5K Following Product Developer @ SAP, Product Security, AppSec, Data Privacy, GDPR. Tweets are personal. RTs aren't endorsements.
Shashank Pachava @PachavaShashank
28 Followers 3K Following
Hao Ke @kehao95
90 Followers 1K Following Engineering & Research, Developing Quine(https://t.co/oXsdZNFwCU)
Aish Fenton @aishfenton
2K Followers 2K Following Wrangling models @ OpenAI, Kiwi, and cat dad. He/Him.
Lei Zhang @JamesZhang0365
86 Followers 238 Following Ph.D. student at SIAT, CAS | Prev @Alibaba_Qwen | Agentic Coding | Agentic RL | Agentic AI Infra.
DEBIDUTTA PANIGRAHI @DEBIDUTTAP24149
30 Followers 2K Following
Vivek Pandit @cricvivek
94 Followers 3K Following

Ankur Bohra @AnkurBohra9
53 Followers 5K Following
PanteraOS @opanteraos
252 Followers 6K Following IA sem hype, eu testo antes de opinar. O que os labs globais lançam, filtrado e benchmarkado em PT-BR.
Sasikanth Kotti @kotti_sasikanth
671 Followers 5K Following Graduate Student @iitjodhpur @CSEIITJ1 / Computer Vision, Trusted AI, Deep Learning. Volunteer Research Engineer @openminedorg. @ml_collective and @forai_ml

rob @Clucks_Crunch
6 Followers 1K Following
Ben Slater @BenASlaterUK
0 Followers 526 Following
Praveen Selvaraj @pravsels
576 Followers 856 Following Co-Founder at Safe Robotics | aspiring hardware thrasher


tech @ljpx00
15 Followers 716 Following
Gabriel Synnaeve @syhw
17K Followers 1K Following Nerd & Dad. RL & CodeGen research since before it was cool.
Hamid Kazemi @hamid_kazemi22
411 Followers 376 Following Research Scientist @Apple | PhD @UMD | AI Safety & Interpretability
Own Aether @ownaether
58 Followers 2K Following ΩWNÆTHER: The Everything, Everyday App That Rewards. Multi AI, Personal AI Layers, Agentic AI, and AI OS. Intelligent A.I. Infrastructure & AI Orchestration
kip @Kipothy
38 Followers 91 Following

General Reasoning @GenReasoning
5K Followers 0 Following A long-horizon reinforcement learning company.
Ross Taylor @rosstaylor90
11K Followers 1K Following Co-founder and CEO @GenReasoning. Previously lots of other things like: reasoning lead Meta AI, Llama 3/2, Galactica, Papers with Code.
Chengxi Taylor @ChengxiTaylor
401 Followers 16 Following Co-Founder & President @GenReasoning | Co-Chair, @UniofOxford Saïd Alumnae Leaders Group | Founder, SEENTrends for United States
You might like



















